 (a) |
 (b) |
 (c) |
 (d) |
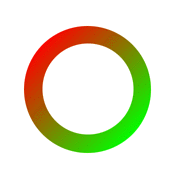
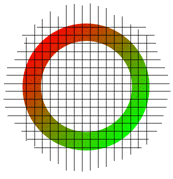
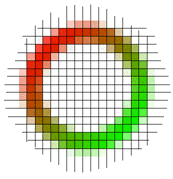
Figure 1: Image rasterization.
by Charlton D. Rose
20 Oct. 1997
There was a time when computers seemed to be nothing more than very expensive calculators. However, as prices fall and technology improves, computers are finding their way into every niche of life. With buzzwords like "multimedia," "Internet," and "database" now infecting every conversation, the personal computer has far exceeded the status of "word processor" and is now a device through which people attempt to organize every aspect of their lives.
Along with the success of the personal computer has come the success of the Internet. If the computer can finally be called a standard household appliance, then the Internet ought to be considered a standard household "utility." Indeed, to some people it is more important than gas, electricity, or water -- well, at least cable TV.
What most people think is "the Internet" is really just the World Wide Web, an application that makes use of the Internet. Although the World Wide Web began life as a simple protocol for publishing hyperlinked text, in recent years it has blossomed into a graphically rich publishing arena where novices and experts sport the their best "web art." These days, one is hard pressed to find a web page that doesn't contain an image of some sort, so it can justifiably be said that the Web is the world's largest digital image repository.
Digital imaging is the practice of managing graphical information in a format that can be understood by computers. For desktop and web publishers, the need for digital imaging is obvious. Intense competition between publishers, combined with high expectations from clients, has increased the need to have a wide variety of publishing tools at one's disposal, including an arsenal of clip art and images. Of course, publishing is not the only practice that has benefited from digital imaging; historians and scientists also use digital imaging to efficiently process large quantities of graphical data.
The construction of a digital image library involves three main steps:
Figure 1: Image rasterization. |
Because most images do not naturally exist in digital form, the first step in building a digital image database is to obtain digital representations for each image. This step is commonly known as "scanning." Besser and Trant (Besser 95) describe scanning as
a process that generally resembles photography or photocopying. Depending on the type of capture device, the image to be scanned may be placed either in front of a digital camera lens . . . or on a scanner. . . . A shot is taken, but instead of exposing the grains on a piece of negative film or on a photocopying drum, light reflects off . . . the image onto a set of light-sensitive diodes. . . . Each diode responds like a grain of film, reading the level of light it is exposed to, except that it converts this reading into a digital value, which it passes on to digital storage.
Digitization is the process of representing ideas or objects in digital form. For images, the most common form of digitization is rasterization. This process is illustrated in Fig. 1. First, the original image (a) is partitioned into a two-dimensional array of square sections (b). Each division will be used to form what is commonly called a pixel, or picture element. Next, the scanning device chooses a single color to represent the entire square (c), which it then transmits to the computer. After the computer has received color values for each section, the entire image can be reconstructed by outputing pixels with the same pattern of color values, either on a monitor or on a printer.
Unfortunately, the rasterization process always trades detail for digitization. The loss is often negligible, but it has the potential to lower the image's quality. Three main parameters determine the quality and success of a scan: pixel resolution, color depth, and noise. These are described below.
Pixel resolution is the fineness of the divisions into which the scanner partitions the image. When the divisions are extremely small, the scanner is said to have high resolution; when the divisions are course, the scanner has low resolution. Resolution is often measured in terms of dpi, or "dots per inch." Given a certain amount of money that one is willing to invest in a scanner, there are physical limits in the degree of resolution that the scanner will support. Even in high resolution scans, the entire pixel must still be approximated by a single color. Afterwards, it is impossible to determine if a slightly different color might have existed between two adjacent samples.
Color Depth refers to the number of unique colors that the scanning device can recognize. Given n, the number of bits (i.e., 0's or 1's) used to represent a pixel's color, the maximum number of unique colors that the scanner can report is 2n. For example, if two bits are used to report a color, then the reported color must be one of 4 available choices (00, 01, 10, or 11). Because of this limitation, both the scanner and computer are forced to represent the entire color spectrum with a limited palette of colors. During a scan, if a color is observed that is not present in the palette, the closest matching color must be chosen instead. Clearly, this approximation reduces the accuracy of the scan.
Noise results from imperfections in the scanning equipment and scanning environment. Scanners are not the only devices susceptible to noise, however; all image reproduction techniques suffer from it. This is what makes copies of copies of copies so noticeably different from the original.
These limitations paint a pretty gloomy picture (no pun intended). With all of these factors limiting the accuracy of image rasterization, why is it ever done at all? Although the effects of these limitations can never be completely avoided, they can be controlled to lie within acceptable limits. In some cases, humans cannot identify differences between an original image and its digitized equivalent.
There are situations, however, when no degree of scanning precision can produce an image that is identical to the original. This is because the human eye is capable of perceiving colors that image output devices, such as monitors and printers, cannot produce. This problem is addressed by a special field of study relevant to digital imaging: color theory. Since our understanding of what colors are and how humans perceive them is essential to the development of image archiving systems, we shall consider a few of the color models currently in use.
For black and white images, pixel representation is simple: a single number is chosen to represent the brightness of each pixel. Zero is usually chosen to represent pure black, and the largest available number is used to represent pure white. The numbers in-between, of course, represent progressive shades of gray. This grayscale model is both intuitive and easy to implement. For black and white images, few other models are known or used.
For color images, however, there are many choices, each with varying strengths and weaknesses. Some color models describe colors in terms of primary colors, which are mixed with different strengths to produce additional colors. Other models are based on human factors, or on the manner in which humans describe or perceive colors. Four commonly used color models are:
|
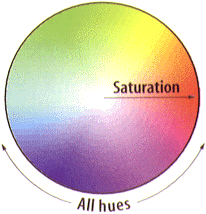
The HSB color model, shown in Fig. 2, is an intuitive model for describing colors because it describes colors the way humans describe them -- in terms of hue (H), saturation (S), and brightness (B). The hue of a color corresponds roughly to the color's class ("yellowish," "bluish," "greenish," "reddish," etc.) and is indicated by a color on the standard color wheel (Fig. 2a).
A color's saturation is its pureness or strength, measured from 0%/gray to 100%/pure. The brightness, of course, refers to the overall lightness or darkness of the color and ranges from 0%/black to 100%/full intensity (Fig. 2b).
Unfortunately, the HSB model is difficult to directly support in hardware. It also suffers from mathematical complications due to the fact that HSB does not define a 1-to-1 correlation between values and colors. However, the HSB model is useful for helping humans describe colors, and is therefore utilized in interactive programs that require the users to identify colors -- such as in an image database search engine.
The CMYK color model describes colors as combinations of cyan (C), magenta (M), yellow (Y), and black (K). To understand how this model works, it is helpful to think of a watercolor artist mixing colors on a white canvas. A new canvas appears white because it reflects all colors. When a canvas is stained with pigment, however, it loses its ability to reflect certain colors. In other words, the pigment acts as a filter that allows only certain light wavelengths to shine through. By repeated application of different pigments, the artist narrows the range of colors that shine through, until the combination of the remaining wavelengths -- the "survivors" -- produce our perception of the desired color.
Most colors can be produced by combining cyan, magenta, and yellow pigments, so these three colors are called subtractive primary colors. In theory, when all three of these colors are subtracted from white, the resulting color is black. In practice, however, the result is a dark, muddy brown, due to impurities in the pigments. Pure black is added to compensate.
It is conceivable that computers could use a CMY or CMYK model to represent color values in a digital image. This seems especially appropriate for images that were originally generated through subtractive color mixing, such as paintings. However, image archivers rarely use CMYK for digitization because there are other color models, with similar performance, that require only three values per pixel, rather than four. This model is not obsolete, however, because it is still used whenever color images are printed.
The RGB color model describes colors as combinations of red (R), green (G), and blue (B). Unlike CMYK, however, these colors are added to black, rather than subtracted from white. In a completely dark room, red, green, and blue lights can be turned on, and their intensities controlled, to produce nearly any imaginable color. Not surprisingly, red, green, and blue are called additive primary colors. Because computer monitors use red, green, and blue phosphors to produce their colors, RGB is the most commonly used model for digital images.
|
All of the color models discussed so far have two serious drawbacks: device dependence and gamut limitations. Device dependence is the phenomenon that allows two output devices to display different colors given identical input. For example, if you place two television sets side by side and tune them to the same channel, you can most likely observe color differences between the two images -- even though they are attempting to display the same content. Device dependence is a serious problem to the image librarian if his goal is to maintain the fidelity of works of art. Of course, the manner in which output devices show colors could be standardized, but there are already so many digital images that have been generated without the standards that few would be willing to "start all over."
Another limitation of the RGB and CMYK color models is that they have limited gamuts, or ranges of colors that they can express. Although RGB encompasses most of CMYK, there are also colors in CMYK that are not expressible in RGB (see Fig. 3). This means that when paintings are digitized into the RGB model, there is a risk that some colors will not be accurately reflected.
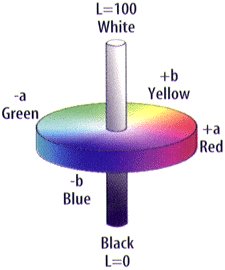
The L*a*b color model was invented to overcome both of these limitations. It expresses colors in terms of a lightness (L) and two chromatic elements, which range from green to red (a) and blue to yellow (b). As Fig. 3 illustrates, the L*a*b gamut is much broader than either of the CMYK or RGB gamuts and contains them entirely.
Because L*a*b is device independent and incorporates a much greater portion of the colors that the human eye can perceive, it seems like a good choice for digital imaging projects. Unfortunately, L*a*b is not very well known or understood. In fact, due to its European origin, most people in the United States have never even heard of it. L*a*b is significantly more complex than RGB, so the hardware, software, and labor required to support it are usually more expensive. For these reasons, few people actually use the L*a*b model.
In large databases where storage space is at a premium, librarians can reduce the size of image files through a technique called compression. Image compression reduces the amount of memory required to store an image by representing it in a more efficient way, or by discarding useless or less important information from the image. Depending on the types of images to be compressed and the requirements of the users who will be accessing them, compression can be used to reduce file sizes from 25 to 95 percent.
Many algorithms are available for compressing image data, but they can be broadly divided into two main categories: (1) lossless compression and (2) lossy compression. Lossless compression reduces file sizes by abbreviating portions of the image data that can be predicted from the surrounding context. Images compressed by lossless methods can be reconstructed to produce the original image. Lossy compression, on the other hand, works on the principle that images contain useless data that can be discarded without affecting the images' quality. Images compressed through lossy techniques cannot be used to derive an exact replica of the original image. However, the differences between them may be slight and visually unnoticeable (see Fig. 4)
Figure 4: Compression methods. |
In order to guarantee that image data can be decoded and viewed by a wide variety of people for many different purposes, it is wise to choose a file format that is both well-defined and widely implemented [Besser 1995]. Unfortunately, because there are so many graphic formats currently in use, choosing a single format that best fits the user's needs and is supported by all graphics applications is not a trivial problem. Furthermore, there are many "dialects" within each format, so that reliably implementing even one of them becomes an enormous undertaking. Many graphic file formats incorporate one or more compression techniques, so choosing a particular file format also restricts one's choices of available compression algorithms, and vice versa. Some commonly used file formats are described below.
In an attempt to standardize the representation of color images distributed throughout their network, Compuserve introduced a format called the Graphics Interchange Format (GIF). While GIF enjoyed modest popularity before the explosion of the World Wide Web, it did not become as popular as it is now until HTML browsers could support it. Presently, there are millions of GIF image scattered all over the Internet.
GIF incorporates a compression algorithm called LZW, after its inventors, Lempel, Ziv, and Welch. This lossless compression algorithm replaces repeated sequences of data with references to the first occurrence, thus decreasing the size of the image data. LZW works best with flat-color images, such as filled-in pictures taken from a child's coloring book. LZW does not perform as well for continuous-tone images, such as photographs of natural scenery. This is because LZW cannot yield good compression unless the image contains repeating color values. In a flat-color images, green is always green, but in a photograph of grass, there may be hundreds of shades of green -- each one microscopically different from the other, none of them ever repeating. In these cases, LZW can backfire, producing files that are larger than the original!
Since GIF is optimized for flat-color images, it is not surprising that it can only support images containing 256 colors or less. In order to represent true color images, such as a photograph, in the GIF format it is first necessary to select a palette of 256 colors, and then coerce every pixel in the image to be one of those colors. This process is called palette reduction. When the original image contains colors that are not close to entries in the palette, a process called error diffusion can be used to "fake" the extra colors by using pixels of alternating colors from the palette.
Fig. 5 demonstrates the effects of palette reduction by showing what happens to the medallion in Fig. 4 when the entire image is reduced to a 256 color palette. (a) shows what happens when the entire RGB color space is divided into 256 equal portions and the closest match is chosen for each pixel. (b) and (c) are the (much better) results obtained by making a more appropriate selection of colors. (c) shows what happens when error diffusion is used to simulate colors missing from the palette.
|
Although GIF's compression algorithm is lossless, forcing an image to conform to a limited palette is an extremely lossy process. As Fig. 5 demonstrates, the visual effects of this process can be controlled to some degree, but the loss is usually unacceptable in situations where further processing of the image might be necessary. For this reason, GIF is not versatile enough to be considered for image preservation projects where future uses of the image cannot be predicted.
In the fall of 1986, the Aldus Corporations published version 3 of a digital imaging standard called the Tagged Image File Format (TIFF). (The first two versions were drafts that were never published.) In April 1987, Aldus and Microsoft collaborated to produce TIFF revision 4, and since that time the standard's popularity has risen significantly. In a joint publication, Aldus and Microsoft claim that the format's purpose is "to promote the interchange of digital image data. . . . TIFF is intended to be independent of specific operating systems, filing systems, compilers, and processors" [Aldus 1987].
If cross-platform, software-independent image exchange was TIFF's mission, then few can deny its mission has been accomplished. Having become one of the most commonly used formats for lossless true-color image storage, nearly every graphics processing application -- and many desktop publishing systems, too -- include the ability to read TIFF images.
TIFF was designed with extreme generality in mind. "[A] very high priority has been given to structuring the data in such a way as to minimize the pain of future additions," claims the standard. "TIFF was designed to be a very extensible interchange format." Unlike the GIF format, TIFF is not limited to images containing only 256 colors, although it support these too. TIFF also supports a wide variety of color models, including RGB, CMYK, and L*a*b.
These features alone are sufficient to justify TIFF's use as an image archival format, but there is more. TIFF supports textual annotation fields embedded directly in the file, making it ideal for preserving related meta-information (information about information), such as the image's name, author, date and place scanned, etc. Many image filing systems take advantage of these annotation fields, including the Associated Press Picture Desk system [Adobe 1996].
TIFF files can be either compressed or uncompressed. If compression is used, the algorithm chosen is usually LZW, but other methods are also supported. As mentioned earlier, LZW is not always effective on noisy, continuous-color images and sometimes makes files larger.
TIFF's greatest strength -- its generality -- is also its greatest weakness. Because it can do so much, many software applications are unable to support all of its capabilities. This result in software products that appear to be TIFF-compatible, but in fact are incapable of exchanging data with each other. The TIFF specification has often been revised -- on Aug. 1988, November 1989, April 1990, and June 1992, to name a few occasions -- which is the reason why it has not been easy for the graphics industry to adopt a stable, well-understood standard. Nevertheless, the TIFF specification has survived and is still in wide use.
As we noted earlier in regards to Fig. 4, lossless compression techniques can sometimes produce files that are larger than the original. The notion that compression can actually enlarge files runs contrary to intuition, because we would expect that images contain large amounts of redundant information and should therefore be quite compressible. The words "lossy compression" sometimes cause consternation, because most people would like to preserve image quality as much as possible. The truth is, however, that the components in image data that makes lossless compression inefficient are also components that we can do without. Witten, Moffat, and Bell summarize the problem as follows:
[P]articulary with grayscale or color images, it may be that the lower-order few bits of each pixel are really just generated by noise in the digitization process, and are therefore effectively random. This means that they have no appreciable effect on image quality, and also that they are incompressible, since it is impossible to compress random data. Consequently, one may find that a significant fraction of the bandwidth needed to store or transmit the image is dedicated to conveying information that is completely irrelevant! Of course, this makes an overwhelming case for approximate rather than exact representation. [Witten 1994]
Discarding image noise to enhance compressibility is the key to the JPEG format, which incorporates a lossy compression algorithm invented by the Joint Photographic Experts Group. Because JPEG uses lossy compression, an image compressed with JPEG will differ from the original when it is decompressed. Fortunately, the JPEG standard defines a user-tunable parameter to control the compression level, i.e., the aggressiveness with which the algorithm discards data. Thus, a compressed image's quality can be controlled to lie within tolerable limits.
Because JPEG's lossiness accumulates each time images are decompressed, edited, and recompressed, JPEG is not suitable for applications that require intermediate storage (JPEG FAQ 1997). In archival projects where the future use of image data cannot always be predicted, it is best to use a lossless storage format, such as TIFF or PNG (described below). In other words, JPEG is designed for the presentation -- rather than the preservation -- of image data.
LZW, the compression algorithm used in GIF and TIFF, is patented and owned by the Unisys Corporation. It was not until GIF had achieved widespread, global use, however, that the corporation publicly announced its ownership of the patent. Naturally, Unisys was interested in exploiting the world's dependence on LZW by muscling royalty payments from every company that used it.
Of course, the Internet community unanimously cried "foul," but there was no legal recourse. To overcome the legal entanglements of LZW compression and to avoid paying "GIF taxes," a group of volunteers invented the Portable Network Graphic format (PNG). First published in March 1995, this format incorporates all of the still image features available in GIF and TIFF, plus many more that were needed -- and it is completely patent-free. Contrary to the notion that nothing good is free, the compression algorithm built into PNG usually outperforms LZW, both in flat-color images and in continuous-color images!
An attractive feature of PNG is its ability to include gamma information, which describes the lighting characteristics of the system through which the image was acquired (scanned) or processed (edited). Gamma information can be used to reduce the negative impact of device dependencies (discussed earlier) and makes it possible for different output devices to produce visually identical results.
PNG is fairly new and has not yet achieved widespread use. It is my speculation, however, that it will soon be supported by World Wide Web browsers, and when that happens, it is likely to achieve widespread use.
The popularity of the Internet, along with rapid declines in the cost of scanning, has resulted in a plethora of digital images for many applications. While large collections of images are useful, unless they can be organized into a system that facilitates easy retrieval, many of the images might as well be lost. There is no point in storing an image if it cannot be retrieved. This is the motivation behind digital image databases.
In order to build an effective image database, techniques must be developed for compiling, indexing, and searching the images.
The process of compiling images is simply that of deciding which ones will go in the database, and then acquiring them in digital form. Once acquired, the librarian must select a suitable storage format and then save the image to permanent storage. (Many of the facets relating to this stage of database construction have already been discussed in the previous two sections.) Although techniques have been developed to help automate the compiling process, in most cases, human intervention is required. According to Besser,
[t]he image-capture process is very labor-intensive and therefore costly. Image capture, combined with cataloging and indexing, may account for 90 percent of the cost of building an image database. [Besser 1995]
As images are added to a database, the librarian must make sure that the images are indexed in a manner that facilitates later retrieval. Most techniques for indexing images fall into two broad categories: indexing by annotation and indexing by content. Arguments have been made to favor one type over the other, but the science of image database management is still young, and it is hard to tell which one will gain the most widespread use.
Indexing by annotation requires an agent to complement the image data with textual information about the image. With annotations in place, queries can then be made into the database which are resolved by searching through the annotations, rather than the actual image data in which the user is interested. For annotated image databases, the problems and issues of database construction, management, and query are nearly identical to those which exist for textual databases.
Depending on the type of image, annotating can be easy or difficult. For example, a database of well-known historic paintings can simply be indexed by each painting's name, and perhaps the artist's name also. For images that don't have proper names or references, however, it might not be clear how to annotate them. In these cases, it is up to the librarian to offer a subjective description.
Unfortunately, there may be many different ways to describe the same image. This ambiguity reduces the effectiveness of annotation-based searching, especially if the search facility does not automatically account for synonyms. To address this problem, efforts have been made by various institutions to develop structured vocabularies, or rules to unambiguously determine how each image should be described. Some of these vocabularies include the Library of Congress Subject Headings, ICONCLASS, the Thesaurus of Geographic Names, the Art & Architecture Thesaurus, and the Union List of Artist Names [Besser 1995].
The proponents of content-based indexing argue that a picture is worth a thousand words, and that there are many pictures which may not be expressible in words. Content-based indexing techniques use artificial intelligence and pattern recognition to automatically derive information about each image's characteristics. This makes it possible to pose queries such as, "find images containing shades of black in the bottom and shades of blue in the top" (volcanic beaches).
One idea for content-based query that has generated much stir in recent years uses a data structure called a 2D string. This structure enumerates the objects contained in an image and their positions relative to each other. 2D strings contain enough information to reconstruct a symbolic representation of the image, but since the information is only symbolic, the representation is much more compact, thus suitable for use in query matching.
When queries are posed as 2D strings, the task of finding similar images is a simple problem of 2D substring matching [Chang]. Unfortunately, it is difficult to generate 2D strings without human intervention, because the objects represented in the string must first be identified [Tang 1996]. Thus, the 2D string approach represents a compromise between annotation- and content-based indexing. Algorithms for creating and processing 2D strings have been generalized and refined by many contributors [Lee, Petrakis, Tseng].
Huang and Jean [Huang 1995] have proposed a method of indexing images according to their "morphological skeletons." These skeletons are extracted from images by dividing them into feature-based subsections and representing the "bones" with center points and radiuses. Users pose queries by drawing a sample image, from which a "query skeleton" is derived. This query skeleton is then compared to the precomputed skeletons of images in the database and matches are retrieved.
Other image indexing techniques derive general information about an image's color features at various coordinates in order to support queries by example. Chang [Chang 1979], Hirata [Hirata 1992], Kato [Kato 92], and Jacobs [Jacobs 1995] have all described techniques that make this possible. First, the features of each image are extracted using various pattern recognition techniques and saved in an index file. Later, when the user makes a query, he or she can provide either a sample image from the database or a hand-drawn example. In the former case, the features of the query image have already been computed; in the latter case, the features can be quickly derived because the hand-drawn image is not likely to be very complex. The features of the query image can then be compared to the precomputed features stored in the index file, and if similarities are found, the relevant images will be presented to the user.
Jacob's technique [Jacobs 1995] uses a process called "wavelet decomposition" to generate signatures for each image in the database, which are later compared to the query image's signature. Jacob's technique reportedly supports up to 20,000 image comparisons within a tolerable wait time.
Unfortunately, query-by-example techniques are often "not robust to different scales, rotations, and small changes in the location of objects" [Tang 1996]. Still, the system proposed by Hirata and Kato is already being used in an art gallery application, so it must be somewhat useful.
Swain [Swain 1991] suggests the use of color histograms for comparing images. The advantage of this is that it is immune to rotations and scaling, but it also forces the user to consider the colors of the entire image, when in fact she may be interested only in the horse that appears in the center.
QBIC (Query by Image Content), an image database system being developed at IBM, combines shape, color, and texture recognition techniques to support queries by example. This system is touted as one of the best content-based query systems available and is already finding its way into a few commercial applications. According to Tang [Tang 1996], the QBIC system has several attractive features:
"[I]mage properties such as its color, location, and distribution are automatically extracted and stored in pattern vectors." In other words, no user interaction is required to index the database.
Searching takes place in the pattern vectors extracted from the image data, rather than the image data itself. This means that query matching takes less time.
The algorithm used to extract pattern vectors is shape-independent, so the user doesn't need prior knowledge of an object's shape before searching for it.
All queries are posed by visual example, so there is no need to verbally express pictures that are difficult to describe.
The color indexing scheme produces sortable keys, making it possible to arrange database entries for faster queries.
The results of each query can be visually inspected by the user, and then graded in order to refine the query.
I visited an IBM web site where the QBIC system is demonstrated, first attempting a search by color layout, and then a search by texture. Fig. 6 shows the results of two test runs. The query images are shown in the upper-left corners of each response.
|
Fig. 6: Queries made on a QBIC system. |
As can readily be observed by the results, a few of the color layout matches seem relevant, but it is difficult to see a correlation between retrieved images in the texture based query. The color layout query may have performed well because it was so simple. The lower half was green and the upper half blue, a situation that is true of a large number of natural images.
We have discussed several important issues that relate to the construction of digital image libraries. First, we described the scanning process, an expensive but necessary step in acquire content for the library. We demonstrated the lossy nature of rasterization and noted how a librarian's choice of color models can effect the accuracy of an image's digital representation.
Next, we discussed image compression techniques and the file formats that use them. We noted the need for well-defined standards that are free of legal complications, and also realized that the best available options are not always the ones that get used.
Finally, we discussed ways in which a collection of images can be indexed and organized into a searchable database. Queries can be made by searching through image annotations or content-based, automatically generated image digests. We concluded our overview of image database technology with a brief look at IBM's QBIC system.
The potential of digital imaging is enormous, and many aspects of our future are likely to be shaped by technological advances in digital imaging technology. According to Besser and Trant,
Few technologies have offered as much potential to change research and teaching in the arts and humanities as digital imaging. The possibilities of examining rare and unique objects outside the secure, climate-controlled environments of museums and archives liberates collections for study and enjoyment. The ability to display and link collections from around the world breaks down physical barriers to access, and the potential of reaching audiences across social and economic boundaries blurs the distinction between the privileged few and the general public. [Besser 1995]
As the digital age overcomes us, many important decisions will have to be made. Which scanning processes and storage formats will be used to build the archives? Where will the world's precious digital images be stored? How will they be accessed, and who gets to see them? How do we protect artists' copyrights, while at the same time taking advantage of the fact that "information wants to be free?" Time will tell if we make the right decisions. Our children will view our decisions with contempt or delight.